


Data Visualization Articulation – Learn the Grammar of Graphics in this article by Dr. Tania Moulik, a Ph.D. holder in particle physics. She has a passion for data analysis and likes to share her knowledge with others who would like to delve into the world of data analytics. She especially likes R and ggplot2 as a powerful analytics package.
ggplot2 is based on two main concepts: geometric objects and the Grammar of Graphics. The geometric objects in ggplot2 are the different visual structures that are used to visualize data. The Grammar of Graphics is the language used to describe the various components of a graphic that represent the data visualization.
Read More: BUSINESS INTELLIGENCE AND DATA VISUALIZATION SERVICES
The Grammar of Graphics is used for the different aesthetics of a graph, such as the coordinate scale, the fonts, the color themes, and so on. ggplot2 uses a layered Grammar of Graphics concept, which allows us to build a plot in layers. Here, we will explore a few aspects of the Grammar of Graphics. You can find the complete code for this article at How To Apply Data Visualization With R and ggplot2?.
Data Visualization – Rebinning
In a histogram, data is grouped into intervals, or ranges of values, called bins. ggplot has a certain number of bins by default, but the default may not be the best choice every time. Having too many bins in a histogram might not reveal the shape of the distribution while having too few bins might distort the distribution. It is sometimes necessary to rebin a histogram, in order to get a smooth distribution.
The RStudio Workspace
So, before we go further, let’s discuss data visualization in more detail. Our first task is to load a dataset. To do so, we need to load certain packages in RStudio. Take a look at the screenshot of a typical RStudio layout, as follows:
Loading and Exploring a Dataset Using R Functions
In this section, we’ll load and explore a dataset using R functions. Before starting with the implementation, check the version by typing version in the console and checking the details, as follows:

Read also: Connecting with BI and Data Visualization
Let’s begin by following these steps:
-
Install the following packages and libraries:
install.packages(“ggplot2”)
install.packages(“tibble”)
install.packages(“dplyr”)
install.packages(“Lock5Data”)
- Get the current working directory using the getwd(“.”) command:
[1] “C:/Users/admin/Documents/GitHub/Applied-DataVisualization-with-ggplot2-and-R”
- Set the current working directory to Chapter 1 using the following command:
setwd(“C:/Users/admin/Documents/GitHub/Applied-DataVisualization-with-ggplot2-and-R/Lesson1”)
- Use the required command to open the template_Lesson1.R file, which has the necessary libraries.
- Read the following data file, provided in the data directory:
df_hum <- read.csv(“data/historical-hourly-weather-data/humidity.csv”)
The following libraries have now been loaded:
- Graphical visualization package:
require(“ggplot2”)
- Build a data frame or list and some other useful commands:
require(“tibble”)
- A built-in dataset package in R:
require(“Lock5Data”)
Use the following commands to determine the data frame details, as follows:
#Display the column names
colnames(df_hum)
Take a look at the output screenshot:

Use the following command:
#Number of columns and rows
ndim(df_hum)
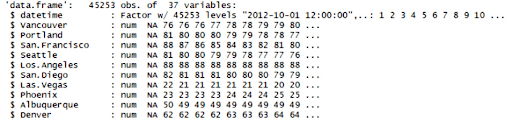
A summary of the data frame can be seen with the following code:
str(df_hum)
Take a look at the output screenshot:
Types of Variables
Variables can be of different types and, sometimes, different software uses different names for the same variables. The following table lists variables and the names that R uses for them; make sure to familiarize yourself with both nomenclatures.
The variable names used in R are as follows:

Exploring Datasets
In this section, we will use the built-in datasets to investigate the relationships between continuous variables, such as temperature and airquality. We’ll explore and also understand the datasets available in R.
Let’s begin by executing the following steps:
- Type data() in the command line to list the datasets available in R. You should see something like the following:

- Choose the following datasets: mtcars, air quality, rock, and sleep.
- List two variables of each type, the dataset names, and the other columns of this table.
- To view the data type, use the str command (for example, str(airquality) ).
Take a look at the following output screenshot:

- After viewing the preceding datasets, fill in the following table. The first entry has been completed for you. The following table includes all variables of the types num and int:

The outcome should be a completed table, similar to the following:

Making Your First Plot
The ggplot2 function qplot (quick plot) is similar to the basic plot() function from the R package. It has the following syntax: qplot(). It can be used to build and combine a range of useful graphs; however, it does not have the same flexibility as the ggplot() function.
Plotting with qplot and R
Suppose that we want to visualize some of the variables in the built-in datasets. A dataset can contain different kinds of variables, as discussed previously. Here, the climate data includes numerical data, such as the temperature, and categorical data, such as hot or cold. However, In order to visualize and correlate different kinds of data, we need to understand the nomenclature of the dataset. We’ll load a data file and understand the structure of the dataset and its variables by using the qplot and R base package. Let’s begin by executing the following steps:
- Plot the temperature variable from the airquality dataset, with hist(airquality$Temp).

Take a look at the following output screenshot:
- Use qplot (which is part of the ggplot2 package) to plot a graph, using the same variables.
- Type the qplot(airquality$Temp) command to obtain the output, as shown in the following screenshot:
 - ggplot2")
Analyzing Various Histograms
The first plot was made in the built-in graphics package in R, while the second one was made using qplot, which is a plotting command in ggplot2. We can see that the two plots look very different. The plot is a histogram of the temperature.
Now, let’s use the humidity data and the first plot that we created. It looks like the humidity values are discrete, which is why you can see discrete peaks in the data. In this section, we’ll analyze the differences between unbinned and binned histograms.
Let’s begin by implementing the following steps:
- Choosing a different type of binning can make the distribution more continuous; use the following code:
ggplot(df_hum,aes(x=Vancouver))+geom_histogram(bins=15)
You’ll get the following output.
Graph 1:

Graph 2:

Choosing a different type of binning can make the distribution more continuous, and one can then better understand the distribution shape. We will now build upon the graph, changing some features and also adding more layers.
- Change the fill color to white using the following command:
ggplot(df_hum,aes(x=Vancouver))+geom_histogram(bins=15,fill=”white”,color=1)
- Add a title to the histogram using the following command:
+ggtitle(“Humidity for Vancouver city”)
- Change the x-axis label and label sizes, as follows:
+xlab(“Humidity”)+theme(axis.text.x=element_text(size = 12),axis.text.y=element_text(size=12))
You should see the following output:

The full command should look as follows:
ggplot(df_hum,aes(x=Vancouver))+geom_histogram(bins=15,fill=”white”,color=1)+ggtitle(“Humidity for Vancouver city”)+xlab(“Humidity”)+theme(axis.text.x=element_text(size= 12),axis.text.y=element_text(size=12))
We can see that the second plot is a visual improvement, due to the following factors:
- There is a title
- The font sizes are visible
- The histogram looks more professional in white
To see what else can be changed, type ?theme.
Changing Boxplot Defaults Using the Grammar of Graphics
In this section, we’ll use the Grammar of Graphics to change defaults and also create a better visualization.
Let’s begin by implementing the following steps:
- Use the humidity data to create the same boxplot seen in the previous section, for plotting monthly data.
- Change the x- and y-axis labels appropriately (the x-axis is the month and the y-axis is the humidity).
- Type ?geom_boxplot in the command line, then look for the aesthetics, including the color and the fill color.
- Change the color to black and the fill color to green (try numbers from 1-6).
- Type ?theme to find out how to change the label size to 15. Change the x– and y-axis titles to size 15 and the color to red.
Hence, the outcome will be the complete code and the graphic with the correct changes:

Refer to the complete code at https://goo.gl/tu7t4y.
Activity: Improving the Default Visualization
Scenario
In the previous activity, you made a judicious choice of a geometric object (bar chart or histogram) for a given variable. In this activity, you will see how to improve a visualization. If you are producing plots to look at privately, you might be okay using the default settings. However, when you are creating plots for publication or giving a presentation, or if your company requires a certain theme, you will need to produce more professional plots that adhere to certain visualization rules and also guidelines. This activity will help you to improve visuals and create a more professional plot.
Aim
To create improved visualizations using the Grammar of Graphics.
Steps for Completion
- Create two of the plots from the previous activity.
- Use the Grammar of Graphics to improve your graphics by layering upon the base graphic.
Refer to the complete code at https://goo.gl/tu7t4y.
Take a look at the following output
Histogram 1:

Histogram 2:

If you found this article interesting, you can explore Applied Data Visualization with R and ggplot2 to develop informative and also aesthetic visualizations that enable effective data analysis in less time. Applied Data Visualization with R and ggplot2 introduces you to the world of data visualization by taking you through the basic features of ggplot2.












Add comment